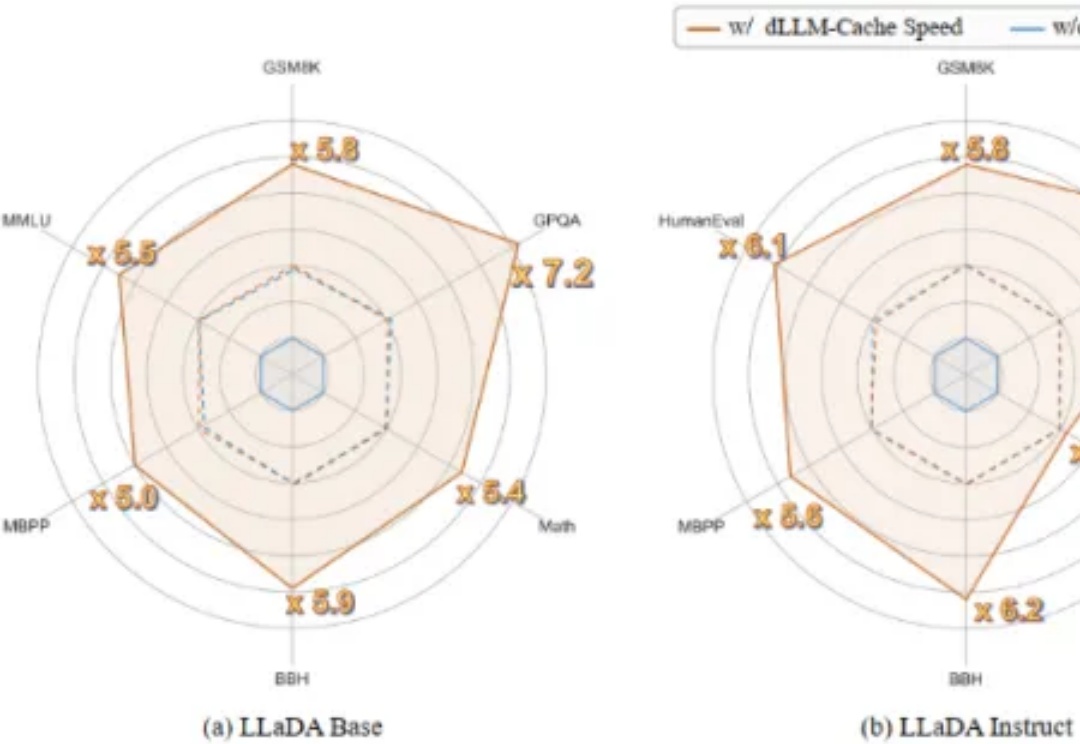
扩散语言模型九倍推理加速!上海交大:KV Cache并非自回归模型的专属技巧
扩散语言模型九倍推理加速!上海交大:KV Cache并非自回归模型的专属技巧首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
来自主题: AI技术研报
11485 点击 2025-05-27 16:22
 搜索
搜索
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
在InternVL-2.5上实现10倍吞吐量提升,模型性能几乎无损失。

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。
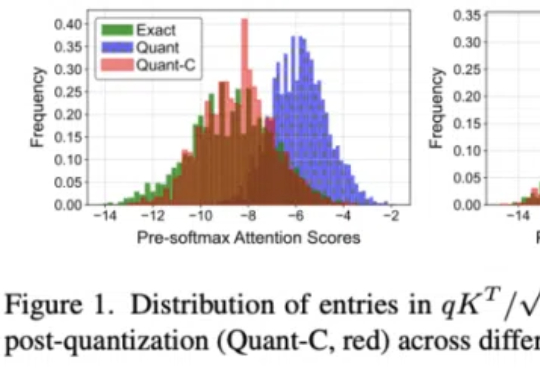
随着当前大语言模型的广泛应用和推理时扩展的新范式的崛起,如何实现高效的大规模推理成为了一个巨大挑战。特别是在语言模型的推理阶段,传统注意力机制中的键值缓存(KV Cache)会随着批处理大小和序列长度线性增长,俨然成为制约大语言模型规模化应用和推理时扩展的「内存杀手」。
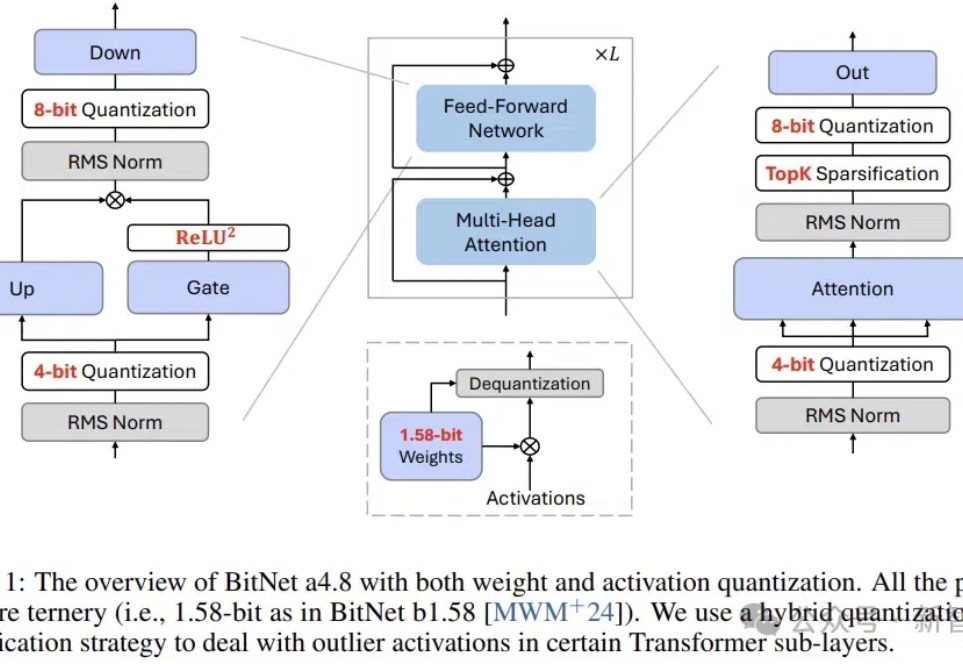
近日,BitNet系列的原班人马推出了新一代架构:BitNet a4.8,为1 bit大模型启用了4位激活值,支持3 bit KV cache,效率再突破。
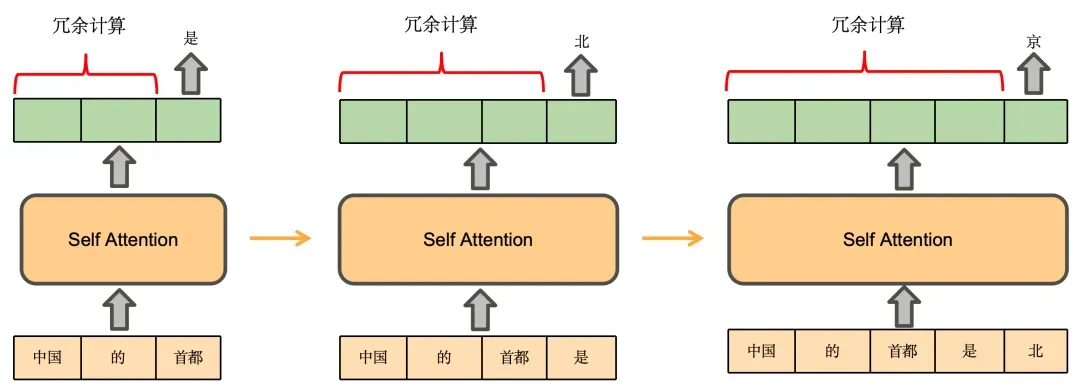
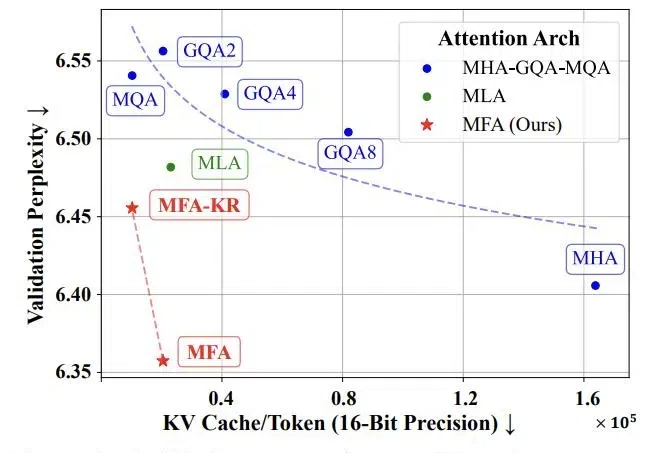
KV Cache 是大模型推理性能优化的一个常用技术,该技术可以在不影响任何计算精度的前提下,通过空间换时间的思想,提高推理性能。

用KV缓存加速大模型的显存瓶颈,终于迎来突破。 北大、威斯康辛-麦迪逊、微软等联合团队提出了全新的缓存分配方案,只用2.5%的KV cache,就能保持大模型90%的性能。 这下再也不用担心KV占用的显存容量过高,导致显卡不够用了。